1. 개요
AWS 인프라에서 EC2는 유연한 컴퓨팅 자원을 제공하지만, 사용되지 않는 인스턴스나 연관 리소스(EBS, Elastic IP 등)가 방치될 경우 비용 낭비로 이어질 수 있습니다. 본 글에서는 AWS SDK for Python(boto3) 와 CloudWatch를 활용하여 ELB기반의 미사용 자원 식별 자동화를 구현하는 방법을 설명하도록 하겠습니다.
이 솔루션은 다음과 같은 환경에 적용 가능합니다:
- 비용 최적화를 위한 자원 스캔 자동화
- 운영 리소스 현황 점검 및 정리
2. 아키텍쳐 및 권한정책 설정
2.1 구성 아키텍쳐
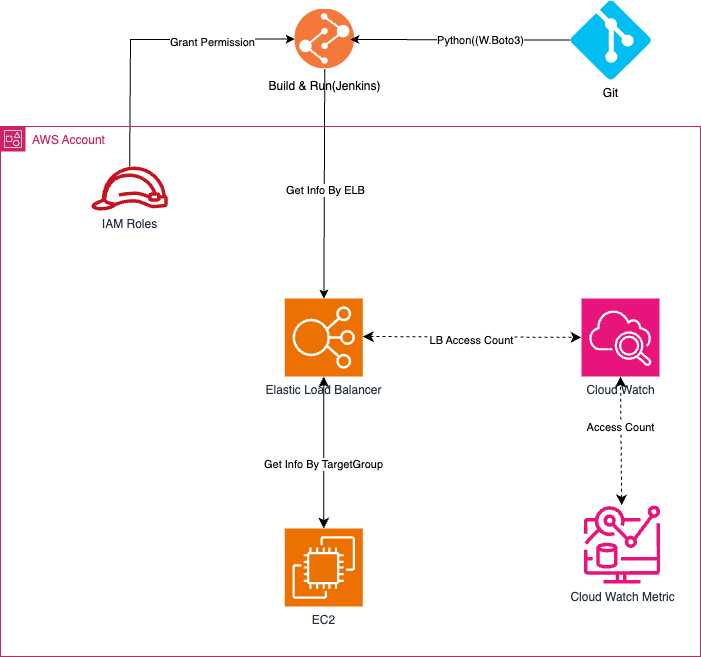
간략히 전체적인 구조를 설명하자면
1) Python으로 개발된 자동화 Source는 Git Sever에 저장되어 있고
2) 매월 1일 Jenkins에서 Build / Run 한다.
3) Application이 구동되면 각 Account에 존재하는 모든 ELB List를 조회하고
4) 조회한 ELB 정보를 기준으로 과거 1개월치의 LB Request Count와 LB 하위 Target Group Request Count를 CloudWatch Metric에서 조회한다.
5) 그리고, 각 Target Group에 속해있는 EC2정보를 조회해서
6) 최종적으로 취합된 정보를 Excel로 생성해서 Mail로 발송하게 됩니다.
2.2 권한 정책 (IAM Role/Policy)
다음과 같은 최소 권한이 필요합니다:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"ec2:DescribeInstances",
"cloudwatch:GetMetricData",
"cloudwatch:GetMetricStatistics",
"elasticloadbalancing:DescribeLoadBalancers",
"elasticloadbalancing:DescribeTargetGroupAttributes",
],
"Resource": "*"
}
]
}3. 식별 대상 정의
이번 자동화 스크립트의 주요 대상은 다음과 같습니다:
| EC2 인스턴스 | ① Request Count = 0 ② Target Group에 속하지 않은 EC2 |
| ELB | ① Request Count = 0 ② Target Group이 없는 ELB |
참고: 태그(Keep=true) 등을 활용한 예외 리소스 필터링 전략도 병행 적용 가능
4. ELB 조회
4.1 Boto3를 이용한 Client 생성
# Instance 접근을 위한 접속정보용 Model Class
@dataclass
class ConnectModel:
account: str
region: str
awsSession: boto3.Session
resultArr: list
# Instance 정보 조회용 Model Class
@dataclass
class ResourceModel:
instType: str
instClient: boto3.Session.client
instClientSession: boto3.Session
# Instance에 대한 Tag를 Control하기 위한 Data Model 생성
def getResourceModel(self, instanceType, connectData: ConnectModel):
if instanceType == config.aws_type_ec2:
instClient = connectData.awsSession.client('ec2', region_name=connectData.region)
elif instanceType == config.aws_type_elb:
instClient = connectData.awsSession.client('elbv2', region_name=connectData.region)
elif instanceType == config.aws_type_cloudWatch:
instClient = connectData.awsSession.client('cloudwatch', region_name=connectData.region)
else:
instClient = None
if self.resourceModel is None or self.resourceModel.instClient is None or self.resourceModel.instClientSession != connectData.awsSession:
self.connectData = connectData
self.resourceModel = ResourceModel(instanceType, instClient, connectData.awsSession)
return self.resourceModelData 가독성과 재활용을 위해 dataclass를 이용했고,
ConnectMode에 각 Account별 접속정보를 할당해서 사용할 InstanceType에 맞춰 boto3 Client를 생성하도록 했습니다.
생성된 Instance별 Clinet는 ResourceMode이라는 dataclase에 할당하여 반환함으로써 코드 가독성과 재사용성을 높였습니다.
4.2 Account하위 ELB 목록 조회
def getLbList(self, connectData: ConnectModel):
resourceModel = self.getResourceClient(connectData)
resultList = []
paginator = resourceModel.instClient.get_paginator('describe_load_balancers')
while True:
try:
resultList = paginator.paginate(PaginationConfig={'PageSize': 50})
except botocore.exceptions.ClientError as error:
self.logger.log_error("Get ELB Instance Info API Error : " + str(error))
if error.response['Error']['Code'] == 'LimitExceededException':
self.logger.log_error('API call limit exceeded; backing off and retrying...')
else:
raise error
finally:
break
return resultListAPI를 이용해 한번에 조회되는 ELB의 갯수에 제한이 있기 때문에 Paginator를 사용해서 전체 ELB의 정보를 반환하도록 했습니다.
4.3 ELB별 TargetGroup 정보 조회
def getLbData(self, connectData:ConnectModel):
# ....중략....
lbList = self.elb.getLbList(connectData)
# self.elb.getTargetGroupList(connectData)
for page in lbList:
for lbInfo in page['LoadBalancers']:
# ....중략....
targetGrouptList = self.elb.getTargetGroupList(orgInfo, False)
# ....중략....
# TargetGroup 목록 조회
def getTargetGroupList(self, resultInfo: ResultModel, isPagination: False):
# time.sleep(self.sleepTime)
while True:
try:
if isPagination:
paginator = self.resourceModel.instClient.get_paginator('describe_target_groups')
resultList = paginator.paginate(PaginationConfig={'PageSize': 400})
else:
resultList = self.resourceModel.instClient.describe_target_groups(LoadBalancerArn=resultInfo.lbArn,
PageSize=400)
except botocore.exceptions.ClientError as error:
# self.logger.log_error("Get LB Target Health Group Info API Error : " + error)
self.logger.log_error('Get LB Target Group Info API Error : {} Error Code : {}'.format(error,
error.response[
'Error'][
'Code']))
if error.response['Error']['Code'] == 'Throttling':
# API Throttling 오류발생시 일정시간 Wait후 재귀호출 처리
time.sleep(self.throttlingTime)
resultList = self.getTargetGroupList(resultInfo, isPagination)
break
else:
raise
finally:
break
return resultListPagenator를 이용해 조회한 ELB정보를 기준으로 하위 TargetGroup List를 조회합니다.
이때, API Throttling이 발생하는 경우가 있어서, 오류발생시 Sleep과 재귀호출을 통해 TargetGroup List를 다시 조회할수 있도록 처리 했습니다.
5. CloudWatch 연동: Request Count 조회
5.1 최근 30일간 Request Count 조회
def getMetricStatistics(self, connectData: ConnectModel, resultData: ResultModel, isTargetGroup = False):
resourceModel = self.getResourceModel(config.aws_type_cloudWatch, connectData)
metricParam = self.getMetricParamModel(self.getBaseMetricParamModel(resultData), isTargetGroup)
try:
result = resourceModel.instClient.get_metric_statistics(
Namespace=metricParam.nameSpace,
Period=2592000, # 30일
StartTime=datetime.utcnow() - timedelta(days=30),
EndTime=datetime.utcnow() - timedelta(days=1),
MetricName=metricParam.metricName,
Statistics=['Sum'],
Dimensions=[
{
'Name': metricParam.dimensionName,
'Value': metricParam.dimensionValue
}
]
)
count = str(result['Datapoints'][0]['Sum'])
except Exception as e:
count = 'X'
return count6. ELB와 연결되지 않은 TargetGroup과 EC2 정보 조회
def getUnUseTargetGroupList(self):
resuList = []
tgPageList = self.getTargetGroupList(None, True)
for pageInfo in tgPageList:
tgResuList = [tg for tg in pageInfo['TargetGroups'] if len(tg['LoadBalancerArns']) == 0]
for tgInfo in tgResuList:
tmpInfo = self.getResultInfoModel()
tmpInfo.tgArn = tgInfo['TargetGroupArn']
tmpInfo.tgName = tgInfo['TargetGroupName']
tmpInfo.protocol = tgInfo['Protocol']
tmpInfo.port = tgInfo['Port']
targetGrouptHealthChkList = self.getTargetHealthCheckList(tmpInfo)
if len(self.getDictionayValue(targetGrouptHealthChkList, 'TargetHealthDescriptions')) > 0:
for healthChkInfo in self.getDictionayValue(targetGrouptHealthChkList, 'TargetHealthDescriptions'):
resultInfo = copy(tmpInfo)
resultInfo.serverArn = healthChkInfo['Target']['Id']
resuList.append(resultInfo)
else:
# self.logger.log_debug('TargetHealthDescriptions Empty : {}'.format(tempInfo))
resuList.append(tmpInfo)
# self.logger.log_debug('Not Use Target Group Info Case : {}'.format(resuList))
return resuList자원을 삭제하다 보면, ELB만 삭제하고 TargetGroup은 삭제하지 않는 경우가 발생합니다. 때문에, ELB에 연결되지 않은
TargetGroup 정보를 식별하고, 해당 TargetGroup 정보에서 매핑된 EC2정보를 조회합니다.
7. 스크립트 통합 구조
7.1 전체 탐색 및 리포트 생성
self.resultArr = []
def runManager(self):
# ....중략....
for self.currentAccount in targetAreaList:
for regionInfo in regionList['Regions']:
self.currentRegion = regionInfo['RegionName']
# ....중략....
connectData = ConnectModel(self.currentAccount, self.currentRegion, awsSession, self.resultArr)
connectData.resultArr = self.resultArr
# ....중략....
#전체 ELB 스캔 및 Raw Data 생성
self.multiConnector.getLbData(connectData)
#Excel 파일 생성
self.makeResultFileData(self.resultArr)
if config.isMakeExcel:
resultFileName = self.excelUtil.makeExcelFile()
if config.isSendMail:
mailUtil.sendMail(resultFileName)
os.remove(resultFileName)
self.logger.log_info("########LB Request Manager Finish########")7.2 Excel 리포트 파일 생성
# 최종 Data로 Excel 파일 생성
def makeResultFileData(self, resultArr):
if (len(resultArr) > 0):
sheetName = self.currentAccount + ' ' + config_excel.subfix
indexKeyField = config_excel.idx_list_arr
while True:
try:
self.logger.log_info('########MAKE ' + sheetName + ' DATA - START##########')
self.logger.log_info('Excel Data Account : {}, Result Count : {}'.format(self.currentAccount, len(self.resultArr)))
self.excelUtil.addWorkSheetData(sheetName, indexKeyField, self.getExcelDataArray(resultArr))
resultArr.clear()
self.logger.log_info('########MAKE ' + sheetName + ' DATA - FINISH##########')
except Exception as e:
self.logger.log_error("Make " + sheetName + " CSV and Send Email Error : " + str(e))
finally:
break
#ExcelManager
import pandas as pd
import pandas.io.formats.excel
class ExcelManager:
def __init__(self, logger):
self.logger = logger
self.excelData = []
self.excelWriter = None
pandas.io.formats.excel.header_style = None
def addWorkSheetData(self, sheetName, keyFieldArr,dataArr):
data = {'sheetName': sheetName, 'title': sheetName, 'keyField': keyFieldArr, 'datas': copy.deepcopy(dataArr)}
def makeExcelFile(self):
now = datetime.now()
fileName = 'lb_req_result_'+now.strftime("%Y%m%d")+'.xlsx'
self.excelWriter = pd.ExcelWriter(fileName, engine='xlsxwriter')
# ALL ACCOUNT INFO SHEET DATA 생성
totalData = []
for sheetInfo in self.excelData:
totalData.extend(sheetInfo['datas'])
self.addWorkSheetData(config_excel.all_account +' '+ config_excel.subfix, config_excel.idx_list_arr, totalData)
for sheetInfo in self.excelData:
totalData.extend(sheetInfo['datas'])
sheetName = sheetInfo['sheetName']
if not sheetName.startswith(config_excel.all_account):
sheetName = config_excel.prefix+' '+sheetName
dataFrame = pd.DataFrame.from_records(sheetInfo['datas'], columns=sheetInfo['keyField'])
dataFrame.index += 1
dataFrame.to_excel(self.excelWriter, sheet_name=sheetName, startrow=config_excel.start_row)
self.setWorkSheetStyle(dataFrame, sheetName)
self.excelWriter.close()
return fileName7.3 Excel 리포트 파일을 업무 담당자에게 E-mail발송
def sendMail(fileName=None):
ses = boto3.client('ses', region_name = 'ap-northeast-2')
for to_email in config.to_email_addr:
msg = MIMEMultipart()
msg['Subject'] = config.title_email
msg['From'] = config.from_email_addr
msg['To'] = to_email
# what a recipient sees if they don't use an email reader
msg.preamble = 'Multipart message.\n'
# the message body
part = MIMEText(config.contents_email)
msg.attach(part)
# the attachment
# TODO : 메일 발송시 여러개 파일 한번에 모아서 발송하도록 처리
# TODO : 여러개 파일, 하나의 Excel 파일로 생성해서 보내기
part = MIMEApplication(open(fileName, 'rb').read())
part.add_header('Content-Disposition', 'attachment', filename=fileName)
msg.attach(part)
result = ses.send_raw_email(Source=msg['From'], Destinations=[to_email], RawMessage={'Data': msg.as_string()})
print(result)https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/ses/client/send_email.html
send_email - Boto3 1.38.15 documentation
Previous send_custom_verification_email
boto3.amazonaws.com
8. 결론 및 확장 방향
본 스크립트는 ELB 기반 자원의 장기 미사용 여부를 탐지하는 비용 절감 전략의 출발점입니다. 이후 아래 방향으로의 확장이 가능할 것으로 생각하고 있습니다.
- 자동 삭제 워크플로우 통합
: AWS Lambda와 S3를 추가로 연동하여 S3에 엑셀파일을 저장하고 Lambda를 Trigger해서 담당자에게 메일 발송후 일정기간후 자원을 자동 삭제하는 기능도 추가가 가능할것 같습니다. - 다른 자원군(RDS, S3 등)으로 범위 확장
: 단순히 EC2뿐만이 아니라, 사용량을 기반으로 해서 사용하지 않는 RDS나 S3도 식별하는것이 가능합니다.
9. 마치며
AWS의 최대 장점은 유연한 Computing 환경과 더불어, 거의 대부분의 기능을 SDK를 이용해 Application단에서직접 접근하고 제어할수 있는 점이라고 생각합니다.
이런 부분을 AI기능과 결합해서 사용하게 된다면, 성능과 비용 그리고 효율성까지 3마리 토끼를 모두 잡을수 있을것이라고 생각합니다.
이상, 긴글 읽어 주셔서 감사합니다.
본 글은 MegazoneCloud의 AWS Ambassador 활동으로 작성된 글입니다.
'AWS Ambassador' 카테고리의 다른 글
| AWS DRS서비스를 활용한 DR(Disaster Recovery) 전략 수립 및 적용 (0) | 2025.05.12 |
|---|---|
| [AWS 비용 최적화]AWS Lambda 기반 EC2 자동 중지/시작 솔루션 (0) | 2025.04.23 |
| AWS EKS 기반 Loki 구축 사례 (0) | 2025.04.22 |
| Amazon CloudWatch를 활용한 RDS 모니터링 (0) | 2025.04.15 |