1. 들어가며
월요일 오전 9시, 업무를 시작하자마자 Jira 알림이 쏟아집니다. "쿼리 검수 요청드립니다", "급하게 반영이 필요한데 오늘 중으로 확인 가능할까요?", "이번 주 금요일까지 오픈인데 쿼리 15건 검수 부탁드립니다." 채팅창을 닫기도 전에 새 요청이 도착합니다. DBA라면 한 번쯤 겪어보셨을 이 풍경, 어떻게 대응하고 계신가요?
SA Unit 리더로서 Infra 관련 업무 전반을 총괄하다 보니, 밀접하게 협업을 진행하는 DBA Unit에서 발생하는 위와 같은 업무적인 고충을 가까이서 접할 수 있었습니다. 신규 서비스 런칭이나 대규모 시스템 반영 일정이 겹치면 DBA Unit에는 하루에 수십 건, 일주일이면 수백 건의 쿼리 검수 요청이 밀려들었습니다. 쿼리 1건을 제대로 검토하려면 실행 계획도 뽑아보고 인덱스 구성도 확인해야 하니 평균 20분은 족히 걸린다고 합니다. 그 때문에, 업무 담당 DBA는 요청받은 검수 업무를 수행하다 보면 정작 성능 튜닝이나 아키텍처 개선 같은 더 중요한 업무는 뒤로 밀리는 경우가 많았다고 합니다.
더 안타까웠던 것은, 비슷한 패턴의 문제가 계속 반복되고, DBA마다 판단 기준도 미묘하게 달라, 같은 쿼리가 어떤 날은 통과되고 어떤 날은 반려가 되는 등 업무가 일관성 없이 진행되는 경우도 많은 것 같았습니다. 직접 업무를 담당하는 담당자가 아니라, 한걸음 물러나 생각해 보니 이 반복되는 과중한 업무를 시스템 구성으로 해결이 가능한 문제라는 생각이 들었습니다.
본 글에서는, 위와 같은 이유로 구축하게 된 AI 기반 SQL 쿼리 자동 검수 시스템의 설계와 구축 경험을 공유드리고자 합니다. AWS EC2 GPU 인스턴스와 PostgreSQL, RAG(검색 증강 생성) 기술을 결합하여, 개발팀이 Jira에 쿼리 검수 요청을 올리면 2분 이내에 1차 검수 결과가 자동으로 Comment로 달리는 24시간 상시 운영 체계를 만든 과정과, 그 과정에서 겪은 시행착오까지 솔직하게 담아보겠습니다.
2. 왜 AI 쿼리 검수 시스템이 필요했나
2.1. 기존 방식의 한계
기존 쿼리 검수 프로세스는 개발팀이 DBA에게 직접 요청하고, DBA가 수동으로 검토하는 방식이었습니다. 이 방식의 핵심 문제는 다음과 같습니다.
- 처리 용량 한계: 쿼리 1건당 평균 20분 소요. 하루 수십 건 요청 시 DBA가 다른 업무를 할 수 없는 구조
- 검수 대기 지연: 요청이 몰리는 시기에는 검수 대기만으로 프로젝트 일정이 지연되는 상황 발생
- 일관성 부족: 검토자에 따라 같은 패턴의 문제도 다르게 판단되어 개발팀의 혼선 유발
- 지식 단절: 과거 검수 사례가 체계적으로 축적되지 않아 유사 문제가 반복적으로 발생
2.2. 아이디어의 시작
전환점이 된 것은 어느 날 DBA Unit과 진행한 비공식 미팅에서였습니다.
"우리가 매번 반려하는 쿼리 패턴이 사실 몇 가지로 수렴되지 않나?"라는 의견이 나왔고, 그 자리에서 지난 6개월치 검수 내역을 꺼내보니 전체의 70% 이상이 아래와 같은 유형의 문제였습니다.
- SELECT * 남발: 필요한 컬럼만 지정하지 않아 불필요한 데이터 전송 및 인덱스 활용 불가
- 인덱스 미사용 풀 스캔: WHERE 조건에 인덱스 컬럼이 없거나 함수 적용으로 인덱스가 무력화된 케이스
- 힌트 오남용: 실행 계획을 강제하는 힌트를 무분별하게 사용해 오히려 성능 저하를 유발
업무 자동화를 통해 24시간 이 반복적인 내용들을 자동으로 걸러내고 피드백해 줄 수만 있다면
DBA는 집중해야 할 진짜 문제에 시간을 쏟을 수 있겠다는 생각이 들었습니다.
목표는 단순하게 설정했습니다. "24시간 언제든지 처리 가능한 1차 AI 쿼리 검수 서비스를 만들자." 복잡한 비즈니스 판단이 필요한 2차 검수는 여전히 DBA가 담당하되, 패턴화된 1차 검수는 AI가 처리하게 하여 DBA가 더 중요한 업무에 집중할 수 있는 구조를 만드는 것이 핵심 방향이었습니다. 개발팀이 이미 매일 쓰고 있는 Jira에 자연스럽게 녹아들어야 한다는 것도 처음부터 분명한 조건이었고, 아키텍처 설계는 AA인 제가 직접 맡기로 했습니다.
3. 시스템 아키텍처 개요
3.1. 시스템 아키텍처
전체 시스템은 크게 세 개의 레이어로 구성됩니다. 개발자가 Jira에 쿼리 검수 요청 티켓을 등록하면 Webhook이 자동으로 분석 엔진을 트리거하고, 3단계 파이프라인(구문 분석 → 실행 계획 분석 → RAG 기반 AI 검수)을 거쳐 결과가 Jira 티켓에 자동으로 Comment로 달립니다.
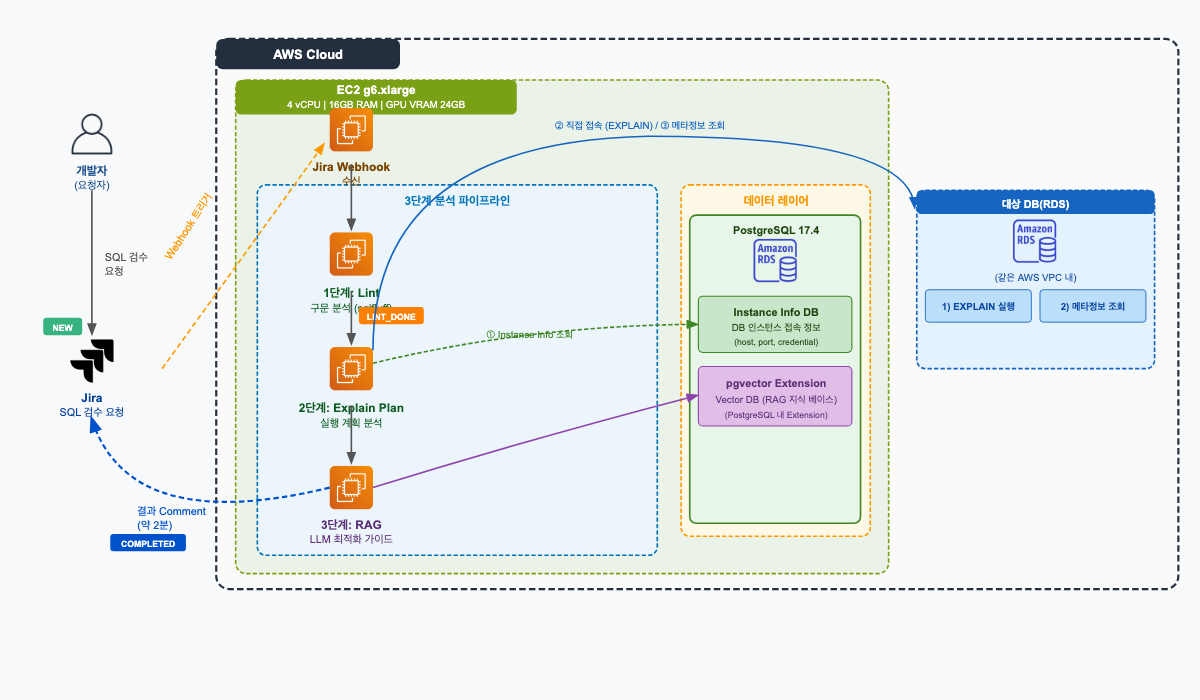
3.2. 사용자(개발자) 관점 워크플로우
개발자 입장에서 실제로 겪는 경험은 단순합니다. 기존에 쓰던 Jira 티켓 등록과 Comment 확인, 딱 두 가지 액션만으로 AI 검수를 받을 수 있습니다. 별도 도구나 절차 없이 일상적인 Jira 워크플로우에 자연스럽게 녹아들도록 설계했습니다.

4. 인프라 구성: AWS EC2 g6.xlarge 선택 배경
시스템 구성 초기에는 Amazon Bedrock 연동을 검토했습니다. 관리형 서비스로 인프라 운영 부담이 없고, Claude나 Titan 같은 고성능 모델을 API로 즉시 호출할 수 있다는 장점이 있었습니다. 그러나 아래의 두 가지 이유로 Local LLM 방식을 선택했습니다.
- 데이터 보안: 이 시스템이 처리하는 SQL 쿼리에는 고객사의 테이블 구조, 데이터 패턴, 비즈니스 로직이 그대로 담겨 있습니다. Bedrock API를 호출하면 이 데이터가 고객사 인프라 외부로 전송될 수도 있는 구조가 되어, 고객사 데이터 보안 정책상 보안성 검토 후 실제 적용까지 시간이 많이 걸릴 것으로 예상되었습니다.
- 비용 효율성: 이 시스템은 내부 테스트 프로젝트로 시작한 사이드 프로젝트입니다. Bedrock API는 토큰 사용량에 따라 호출 비용이 발생하는 반면, EC2에 모델을 탑재하면 인스턴스 운영 비용만으로 쿼리 건수에 관계없이 고정 비용으로 운영할 수 있어 비용 예측과 통제가 용이했습니다.
이에 따라 LLM을 외부 API가 아닌 고객사 환경 내 EC2에 직접 탑재하는 Local LLM 방식으로 전체 인프라를 구성했습니다. 비용과 성능을 고려하여 AWS EC2 g6.xlarge를 선택하였습니다.
로컬 LLM 모델 선정을 위해 24GB VRAM 환경에서 구동 가능한 아래의 LLM들을 검토했습니다.
| 모델 | 파라미터 | VRAM (Q4) | SQL/코드 | 한국어 | Ollama |
|---|---|---|---|---|---|
| Qwen2.5-Coder 32B Instruct | 32B | ~20GB | 최상 | 우수 | 지원 |
| CodeLlama 34B | 34B | ~20GB | 상 | 미흡 | 지원 |
| DeepSeek-Coder V2 Lite 16B | 16B | ~10GB | 상 | 보통 | 지원 |
| Llama 3.1 8B Instruct | 8B | ~5GB | 보통 | 보통 | 지원 |
| Mistral 7B Instruct | 7B | ~4GB | 보통 | 미흡 | 지원 |
검토 결과 Qwen2.5-Coder 32B Instruct (Q4_K_M)를 최종 선정했습니다. 선정 이유는 다음과 같습니다.
- SQL/코드 이해력: Qwen2.5-Coder 시리즈는 코드 특화 모델 중 SQL 실행 계획 분석과 개선 쿼리 제안 작업에서 가장 높은 정확도를 보였습니다.
- 한국어 출력 품질: 검수 결과를 한국어로 출력해야 하는 요구 사항에서, CodeLlama 등 다른 코드 특화 모델에 비해 자연스러운 한국어 생성이 가능했습니다.
- VRAM 여유: Q4_K_M 양자화 기준 약 19~20GB로, g6.xlarge의 24GB VRAM 내에서 안정적으로 운영 가능한 것으로 판단했습니다.
- 배포 편의성: Ollama를 통한 원클릭 배포와 REST API 서빙이 지원되어 FastAPI 백엔드와 간단하게 연동할 수 있었습니다.
| 구성 요소 | 사양 | 선택 이유 |
|---|---|---|
| EC2 인스턴스 | g6.xlarge (4 vCPU, 16GB RAM) | GPU 탑재 인스턴스 중 비용 효율적인 엔트리 티어 |
| GPU VRAM | 24GB | 로컬 LLM 모델 추론에 충분한 메모리 확보 |
| 데이터베이스 | PostgreSQL 17.4 | EXPLAIN ANALYZE JSON 출력, 벡터 확장 지원 |
| LLM 모델 | Qwen2.5-Coder 32B Instruct (Q4_K_M) | SQL/코드 이해력 최상위, 한국어 출력 지원, 24GB VRAM에 안정적으로 탑재 |
| LLM 서빙 | Ollama | 모델 배포 및 API 서빙 간소화 |
| AI 프레임워크 | PyTorch 2.9 (GPU) | LLM 로딩 및 추론 최적화 |
| Vector DB | PostgreSQL + pgvector | 별도 Vector DB 없이 동일 인스턴스에서 PostgreSQL의 pgvector Extension을 이용한 RAG 구성 |
PostgreSQL과 AI 모델을 동일 EC2 인스턴스에서 운영하여 네트워크 레이턴시를 최소화하고,
실행 계획 추출과 AI 분석 사이의 데이터 이동 비용을 제거하였습니다.
5. 3단계 쿼리 분석 파이프라인 상세
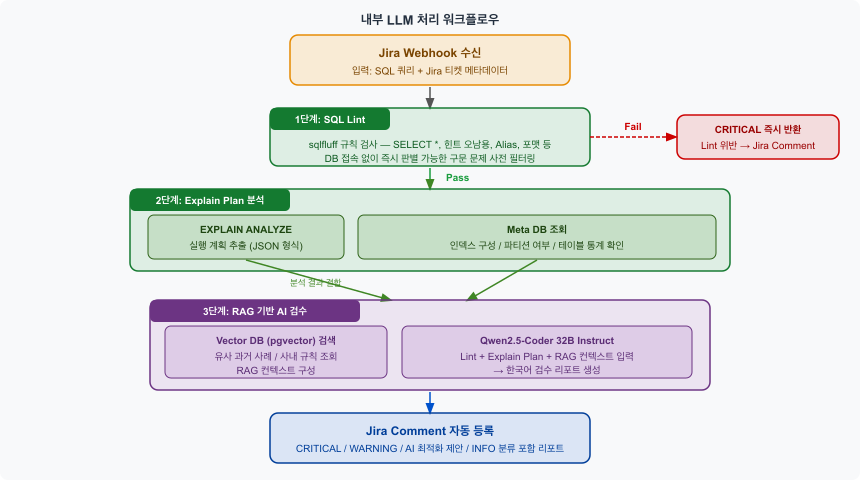
5.1. 1단계: 구문 분석 (Lint)
첫 번째 단계는 SQL 쿼리가 사내 코딩 규칙을 준수하는지 확인하는 구문 분석입니다.
오픈소스인 sqlfluff를 기반으로 사전에 정의한 규칙 세트를 적용하여, DB에서 실제 SQL을 실행하지 않아도 즉시 판별 가능한 문제들을 사전에 필터링하였습니다.
적용 중인 주요 Lint 규칙은 다음과 같습니다.
- SELECT * 금지: 전체 컬럼 조회로 인한 불필요한 I/O 및 네트워크 트래픽 방지
- 힌트 금지 또는 위치 확인: 옵티마이저 힌트 남용으로 인한 성능 저하 예방
- Table Alias 규칙 준수: 가독성 및 조인 오류 방지를 위한 별칭 명명 규칙
- 대소문자 통일: SQL 키워드와 오브젝트명의 대소문자 일관성
- 들여쓰기 및 공백 규칙: 코드 리뷰 효율성 향상을 위한 포맷 표준화
Why Lint?
DB 엔진에서 구문 분석까지 모두 처리하는 방안도 검토하였으나,
Lint 단계는 "DB 접속 전에 잡을 수 있는 문제를 미리 차단"하는 목적입니다.
간단한 규칙 위반을 DB 실행 없이 즉시 피드백할 수 있어 전체 처리 효율이 높아집니다.
5.2. 2단계: 실행 계획 분석 (Explain Plan)
Lint를 통과한 쿼리는 쿼리가 수행될 실제 DB의 정보를 확인한 후, 해당 DB에서 실행 계획을 추출합니다. 단순히 EXPLAIN만 보는 것이 아니라, Meta Data도 함께 조회하여 구조적 문제까지 파악합니다.
실행 계획 분석에서 확인하는 항목은 다음과 같습니다.
- Sequential Scan 탐지: 대용량 테이블에서 인덱스 없이 전체 스캔이 발생하는지 확인
- 통계 정보 최신화 여부: 예측 행 수와 실제 행 수 간 큰 차이 발생 시 ANALYZE 권고
- 인덱스 누락: Meta DB에서 해당 테이블의 인덱스 구성 확인 후 생성 권고
- 파티션 미구성: 대용량 로그성 테이블에 파티셔닝이 적용되어 있는지 확인
- 높은 디스크 I/O: 버퍼 캐시 미스율이 높을 경우 메모리 설정 조정 또는 인덱스 추가 권고
5.3. 3단계: RAG 기반 AI 검수 및 Jira Comment
앞선 두 단계의 분석 결과를 종합하여 LLM이 최종 검수 리포트를 생성하고 Jira 티켓에 자동으로 Comment를 답니다. 이 단계의 핵심은 RAG(Retrieval-Augmented Generation)입니다. 사내 검수 규칙과 과거 검수 사례를 Vector DB에 인덱싱하여, 유사한 패턴의 이전 사례와 해결 방법을 함께 참조하여 더 정확하고 일관된 가이드를 제공합니다.
Jira Comment에 포함되는 내용은 다음과 같습니다.
- Lint 결과: 구문 규칙 위반 항목 및 수정 가이드
- 실행 계획 요약: 주요 성능 이슈와 예상 개선 효과
- AI 최적화 제안: RAG 기반 유사 사례 참조 및 개선된 쿼리 예시
- 우선순위 분류: CRITICAL / WARNING / INFO 수준으로 심각도 분류
실제 Jira Comment에 출력되는 예시는 다음과 같습니다.
[ AI 쿼리 검수 결과 ]
■ CRITICAL
- [Lint] SELECT * 사용 감지 → 필요한 컬럼만 명시하세요.
예) SELECT user_id, name, email FROM users WHERE ...
■ WARNING
- [실행 계획] users 테이블 Sequential Scan 발생 (예상 rows: 1,200,000)
→ idx_users_created_at 인덱스 추가를 검토하세요.
- [실행 계획] 통계 정보 오래됨 (예측 100행 / 실제 85,000행 차이)
→ ANALYZE users; 실행 권고
■ AI 최적화 제안 (RAG 유사 사례 참조)
과거 유사 패턴: 2025-11 users 테이블 풀 스캔 케이스
→ 복합 인덱스 (created_at, status) 추가 후 응답 시간 92% 개선 사례 있음
■ INFO
- 조인 조건 정상, 힌트 미사용 확인됨LLM은 Lint 결과와 실행 계획 데이터, 그리고 Vector DB에서 검색한 유사 과거 사례를 컨텍스트로 받아 위와 같은 검수 리포트를 생성합니다. 단순한 규칙 매칭이 아니라, 과거 사례의 해결 방법까지 함께 제안하는 것이 RAG를 도입한 핵심 이유입니다.
5.4. 내부 LLM 처리 워크플로우
Webhook 수신부터 Jira Comment 등록까지의 내부 처리 흐름입니다. Lint 위반이 심각한 경우 2단계 진입 없이 즉시 반려 결과를 반환하여 DB 연산 비용을 절감합니다.
6. AI와 함께한 3주: 설계부터 배포까지
이 시스템 구축은 제가 수행하는 업무 외에 별도로 수행한 사이드 프로젝트였습니다. DBA 팀의 반복 업무를 줄여줄 수 있겠다는 확신은 있었지만, 백엔드 서버부터 Jira 연동, RAG 파이프라인까지 풀스택으로 혼자 처음부터 끝까지 구현해야 한다는 점은 기본적으로 주어진 업무를 수행하면서 진행해야 하는 도전이었습니다. 때문에, 효율성을 높이기 위해 두 가지 AI 도구를 역할에 맞게 나눠 활용했습니다.
- AWS Kiro (IDE): 프로젝트 Spec 문서 작성과 모듈 인터페이스 정의에 활용했습니다. 각 모듈의 역할, 입력/출력, 의존성을 문서로 정리하는 설계 단계를 AI와 함께 진행했습니다.
- Kiro CLI: 실제 코드 구현 전 과정에 활용했습니다. Jira Webhook 수신 서버, PostgreSQL 실행 계획 추출, RAG 파이프라인, Jira Comment 자동 등록까지 터미널에서 직접 코드를 생성하고 수정하는 데 사용했습니다.
설계가 핵심이었습니다. AI에게 "이런 걸 만들어줘"가 아니라 "이 모듈은 이런 역할을 하고, 입력은 이것이고, 출력은 이것이어야 해"라고 구체적으로 지시할 수 있게 된 것이 결정적이었습니다. Kiro로 Spec을 먼저 정리해 두면, Kiro CLI에서 그 문서를 참조하여 일관성 있는 코드를 생성할 수 있었습니다. 아키텍처 설계 경험이 AI와의 협업에서 품질을 높여준 셈입니다.
그렇다고 순탄하지만은 않았습니다. 가장 큰 문제는 AI가 갑자기 전체 코드 구조를 바꿔버리는 현상이었습니다. Lint 모듈을 수정해달라고 했더니 RAG 연동 코드까지 통째로 재작성해버리는 일이 반복되었고, 처음 며칠은 작업이 계속 원점으로 돌아가는 경험을 했습니다. 이를 해결하기 위해 프로젝트 Spec 문서에 "각 모듈의 수정 사항은 연동 테스트를 통과한 후 즉시 GitHub에 커밋한다"라는 규칙을 명시하고, AI에게도 이 규칙을 지키도록 지시했습니다. 모듈 하나가 동작하면 커밋, 연동 테스트를 통과하면 커밋 — 이 단계별 커밋 규칙 덕분에 AI가 코드를 의도치 않게 변경해도 즉시 이전 상태로 복원할 수 있었고, 전체 개발 복원력이 크게 향상되었습니다.
3주 정도의 시간이 지난 후, 처음으로 Jira 테스트 티켓에 AI의 검수 Comment가 자동으로 달렸을 때의 그 감각은 아직도 생생합니다. 완벽하지는 않았지만, 분명히 동작하고 있었습니다.
이 경험에서 얻은 가장 큰 교훈은, 앞으로의 시스템 구축에서 핵심은 코딩 능력이 아닌 문제를 정확히 정의하고 설계하는 능력이라는 점입니다. 어떤 문제를 풀어야 하는지, 각 구성 요소가 어떤 역할을 해야 하는지를 명확히 알고 있다면, AI는 그것을 실체화해서 구현해 주는 훌륭한 파트너가 되어줍니다.
7. 실제 성과 및 개선 과제
7.1. 정량적 성과
| 지표 | 도입 전 | 도입 후 | 개선율 |
|---|---|---|---|
| 쿼리 1건당 검수 시간 | 약 20분 | 약 1분 | 95% 절감 |
| 가용 시간 | 업무 시간(인력 의존) | 24시간 상시 | 상시 운영 |
| 검수 일관성 | 검토자별 편차 발생 | 표준화된 규칙 기반 | 일관성 확보 |
| 지식 재사용 | 문서 수작업 참조 | RAG 자동 학습/검색 | 자동화 |
7.2. 시스템 도입 시 기대 효과
쿼리 검수 요청이 많은 프로젝트에 이 시스템을 도입하게 될 경우 다음과 같은 효과가 기대됩니다.

7.3. 개선 과제
현재 데모 수준에서 실제 운영 환경으로 고도화하기 위해 반드시 해결해야 할 아래와 같은 과제들도 명확히 인지하고 있습니다.
- 정확도: LLM 할루시네이션(환각) 현상을 최소화하기 위해 고객사 환경에 맞는 RAG 문서 인덱싱 세밀화가 필요합니다. AI 간 교차 검증(1단계 검증 후 2차 AI 재검증)도 검토 중이나 비용이 2배로 증가하는 트레이드오프가 존재합니다.
- 보안: 프롬프트, 데이터, 마스킹 등 암호화 처리가 필요합니다. 현재는 EC2 내부에서 처리되는 구조이나, 추후 VPC 보안 통제 강화(Security Group, VPC Endpoint, 네트워크 격리)와 함께 Amazon Bedrock Private API 연동으로 성능과 보안을 동시에 개선하는 방향을 검토할 예정입니다.
- 운영: AI 모듈 업그레이드, Jira 메인 페이지 변경, 대량 동시 요청 처리, 승인 프로세스 정립 등 운영 유지보수 방안을 수립해야 합니다.
- 비용: EC2 상시 운영 비용, API 토큰 효율화, 자원 사용 비용 최적화 등의 테스트가 필요합니다.
8. 마무리
이 시스템을 운영하면서 가장 인상 깊었던 순간은 성과 지표가 아니라, 어느 날 고객사 개발팀에서 전달받은 메시지였습니다. "예전에는 검수 결과가 올 때까지 다음 작업을 못 했는데, 이제는 Jira에 올리고 바로 다른 일 하다가 Comment 확인하면 돼서 너무 편해요." 그 짧은 한 줄이, 3주 동안 개인 시간을 쪼개가며 시스템을 구성한 보상이 되었습니다.
DBA 팀의 변화도 컸습니다. 예전에는 오전 내내 쿼리 검수에 쏟던 시간이 줄어들면서, 오래 미뤄두었던 인덱스 전략 재설계나 파티셔닝 최적화 작업을 드디어 시작할 수 있게 되었습니다. Lint, Explain Plan, RAG의 3단계 파이프라인을 통해 1건당 검수 시간을 95% 단축했다는 숫자도 물론 의미 있지만, 진짜 변화는 DBA 팀원들이 "이제 쿼리 검수가 무섭지 않다"고 말하기 시작했다는 데 있습니다.
아직 정확도, 보안, 운영 안정성 등 해결해야 할 과제가 남아 있고, 이 시스템은 지금도 계속 고도화 중입니다. 하지만 분명한 것은, 주변 팀의 반복적인 문제를 여러 관점으로 바라보고 구조적으로 해결할 수 있는 시대가 이미 왔다는 점입니다. 중요한 것은 도메인 지식과 문제를 정의하는 능력, 그리고 AI를 파트너로 활용해서 효율적으로 업무를 진행하는 방식입니다.
궁극적으로, AI는 전문가를 대체하는 것이 아니라 전문가가 더 중요한 판단에 집중할 수 있도록 돕는 강력한 도구라고 생각합니다.
업무적으로 비슷한 고민을 하고 계신 DBA나, 아키텍트 담당자분이 계시다면 이 경험이 도움이 될 수 있는 작은 출발점이 되시기를 바랍니다.
 |
AWS의 파트너사인 MegazoneCloud 소속으로 AWS Ambassador로 활동하며 작성한 내용입니다. AWS의 서비스를 소개하고, 실제 업무에서 사용한 사례들에 대한 내용들을 담고 있습니다. |
| Written By. Karam Kim |
'AWS Ambassador' 카테고리의 다른 글
| AWS Kiro를 이용한 Vibe 코딩 Chat Bot 개발 사례 소개 (0) | 2026.02.07 |
|---|---|
| Amazon Q Developer CLI를 활용한 개발 생산성 극대화 (0) | 2025.11.24 |
| 클라우드 컨택센터의 표준 아키텍처 분석: Amazon Connect와 Zendesk 연동 모델 (0) | 2025.10.16 |
| 클라우드 현대화의 두 축: AWS Transform과 Amazon Q Developer transform 심층 비교 (0) | 2025.09.19 |
| 생성형 AI를 통한 EKS 장애 분석 가속화: Amazon Q기반 컨트롤 플레인 지연 현상 분석 (1) | 2025.08.24 |



